用户的算法知识水平及其影响因素分析
——基于视频类、新闻类和购物类算法应用的实证研究
■ 陈逸君 崔迪
【本文提要】算法塑造着我们的数字生活方式。如何认识和理解算法已经成为一种新的媒介素养。既有研究往往聚焦人们在日常网络体验中对算法运作的感知、情感与想象,本研究将算法知识视作特定技术领域的事实性信息,从效果角度考察不同个体对算法技术的实际理解,并探究用户算法知识水平的影响因素,考察不同社会经济地位群组间算法知识差距的调节变量。基于线上调查数据,研究发现不同教育程度的群组间确实存在算法知识沟;媒体报道、用户卷入度和算法编辑能力正向影响用户的算法知识及算法自我效能;出错率遭际不仅可以有效提高用户的算法知识水平,还成为弥合高低教育群组间算法知识水平和进一步缩小并逆转算法自我效能差距的显著因素。
【关键词】算法知识 算法自我效能 算法素养 数字鸿沟 知识沟
【中图分类号】G206
伴随移动互联网的崛起,算法逐步取代传统“把关人”的角色(Gillespie, 2014),成为支配用户与信息相遇、决定用户信息知识范围的“新把关人”(Russell, 2017)。未来,以算法为主导的各类应用将更加深刻地影响人类生活。
算法代表一种新的“用户—技术”关系。在算法情境中,人们并非直接使用或操作算法,而是在有意或无意中与算法展开互动,用户行动与算法机制形成了相互塑造的共生关系。近年来,不少研究尝试分析这种用户与算法的新型关系,提出了算法意识(algorithm awareness)、算法想象(algorithm imaginary)、算法素养(algorithm literacy)和算法的民间理论(algorithmic folk theories)等概念和路径(Eslami, 2015;Rader & Gray, 2015;Gruber et al., 2021;DeVito, 2021;Dogruel, 2021;Swart, 2021)。这些研究更多关注用户对算法的情感反应与文化建构,却少有研究分析用户对算法的事实性认知与理解。为此,本研究聚焦算法知识这一概念,探索用户如何形成对算法及其机制的理解。
在算法日益渗透数字化生存的今天,理解与认知算法的能力至关重要。缺乏对算法的基本理解,用户容易失去对技术的警惕,忽视嵌入代码中的算法歧视及其带来的社会偏见(Goldman,2008),或忽略平台对用户数据隐私的挖掘与滥用。掌握算法知识则有助于人们批判性地评估与反思身处的信息环境。理解算法背后的结构性力量不啻为一种网络实践技能,更是每一位知情公民(informed citizens)的基本媒介素养。
各类算法应用正在成为用户信息获取、娱乐和展开社会交往的主要平台。视频、新闻和购物类平台作为互联网产业生态中的重要领域,三类算法应用共同构筑了当下中国网民的日常生活方式。无论是从用户角度(使用频率、使用时长和使用过程中人们经验情感的生产),产品角度(市场份额、商业化价值),还是从社会功能(娱乐、社交、信息获取和物质消费等多重社会化需求的满足)出发,选取上述三类算法应用都具有一定的典型性和代表意义。此外,本研究还希望超越以往只考察单一算法应用的局限,纳入三种不同类型的算法应用分析其异同。
本研究以算法素养及数字鸿沟为视角切入,探索个体间算法知识差异的成因,考察各类因素在调节算法知识沟中的作用。具体而言,我们结合用户对视频类、新闻类和购物类算法应用的使用经验,聚焦算法知识与算法自我效能两组变量,通过对771名用户的线上调查建立OLS回归模型,分析外生因素、内生因素以及社会经济地位所产生的影响。对用户算法知识的考察,不仅有助于我们深入理解算法知识的影响机制,而且对引导用户理性地、批判地接触和认知算法平台,进而提升公民的算法素养具有启示意义。
一、文献综述
1.算法知识的概念
本研究聚焦于算法知识这一概念,探索用户对算法的认知和理解。既有文献对算法知识的讨论有限,但关于媒介素养、媒介知识及算法感知等相关研究为算法知识的概念化提供了理论基础。首先就生成逻辑而言,算法知识可看作人们对复杂的、不确定的算法技术做出的认知性或感知性反馈。这种认知反馈可能是对算法存在与否的基本知晓(Eslami, 2015;Rader & Gray, 2015;Gruber et al., 2021),也可能是用户在实践中发展出的“民间理论”——自我构建的一套对于解释算法运作机制及其影响的知识框架(DeVito , 2021;DeVito et al., 2017)。有时,这种对算法的认知还体现为一种社会想象(social imagery)。从技术建构的视角出发,Bucher(2017)用算法想象来阐释人和算法的关系。在她看来,实践出真知(knowing through doing)——由于算法知识包含了相关的经验和情感,人们必须通过日常的算法接触才能真正理解算法。
其次,算法知识还可以理解为媒介素养的一个有机组成部分。媒介素养指媒介使用者在面对不同媒体的各种信息时,表现出的信息选择能力、质疑能力、理解能力、评估能力、创造和生产能力,以及思辨的反应能力(黄旦,郭丽华,2008;陆晔,2008)。有学者从媒介素养的角度阐释年轻用户对算法应用的理解、感受及卷入,并发展出“算法素养”这一概念(Swart, 2021)。其中,算法素养包含算法意识、知识储备、想象和围绕算法展开的各种应对策略等多个维度。从媒介素养角度看,算法知识与个体在算法中介环境下形成的“数字技能”或“网络技能”(van Deursen & van Dijk, 2010)紧密相关。
此外,从获取知识的渠道看,算法知识是一种可传播的科学或技术知识。在媒介知识效果研究中,这类知识指人们所掌握的特定科学或技术领域的事实性信息,个体可以通过正式教育、新闻媒介或人际传播等渠道获取这些知识,不同人群对知识的掌握存在差异(崔迪,2019)。如此,算法知识可理解为关于算法的正规的、确凿的事实性信息。这也意味着,人们对算法的理解有正确和错误的区别,人们可以透过不同传播渠道或亲身实践获取算法知识,也可能忘记或错失算法知识。
综合以上三种视角,我们尝试对算法知识进行如下界定:算法知识体现了人们在日常网络体验中对算法运作方式的感知与理解。算法知识来源于人们对算法机制的感受、反思与学习。与算法想象不同,本研究将算法知识理解为人们对算法技术的事实性理解。这种理解存在相对客观的标准,因而在个体间存在差异。例如,算法知识可能包括如下认知:平台内容的时效性或热门程度是算法建构的结果,算法推荐可能受到广告赞助的影响等。同时,算法知识反映了一种广义上的媒介素养。掌握算法知识,意味着用户在当下网络环境中有更大的把握与主动性来选择自己所接受的信息并维护自己的权益。在操作层面,我们一方面对算法知识的客观维度进行考察,测量用户对算法知识的实际掌握情况。另一方面,我们还尝试分析了算法知识的主观维度。为此,本文引入了“算法自我效能”(algorithmic self-efficacy)的概念——个体对自身理解和应对算法机制能力的自我感知与评价,希望通过这两个变量来对比分析算法知识的主观和客观维度。
2.算法知识的影响因素
在考察用户算法知识水平的基础上,本研究将探究算法知识的影响因素。传统知识沟理论认为,社会经济地位高的群体接受信息的速度比社会经济地位低的群体快,因此当大众媒介信息增长时,两群体间的知识差距有增无减(Tichenor et al., 1970)。作为知识沟现象在新媒介技术环境下的延伸,数字鸿沟的研究者认为,社会经济地位和其他人口学变量(如性别、年龄和种族)是造成人们对互联网基础设施的接入(access)、互联网的使用技能和使用目的(usage),以及互联网为个人带来的包括社会连接、专业技能和政治参与等在内的总体效益(beneficial in general)差异的重要原因(van Deursen & Helsper, 2015;van Deursen & van Dijk, 2014)。算法作为当今数字技术的产物,参照数字鸿沟的理论逻辑,社会经济地位同样会影响人们围绕算法技术的事实性理解,从而造成个体间的算法知识差异。一些研究已经证实了算法知识沟的存在,如Gran等人(2020)以挪威用户为研究对象,发现教育水平和地理位置(城市或郊区)会导致用户在算法意识方面的差距。Cotter和Reisdorf(2020)在对美国互联网用户的分层抽样调查中发现,个体的教育程度差异会导致算法知识沟。这些学者以欧美国家作为主要研究场域,本土化语境下的用户群体是否也存在算法知识沟有待考证。基于此,本研究提出假设:
H1:社会经济地位(SES)显著影响用户的算法知识水平/算法自我效能。
人们如何获取和形成对新技术的认知呢?经典研究表明,媒体报道与人际沟通是获取包括公共事务、科学、技术知识等的重要渠道(Ho & Chuah, 2022;Price & Zaller, 1993)。在媒体报道方面,现有研究证实了电视或报纸等传统媒体(Price & Zaller, 1993;Lo & Chang, 2006)以及网络新闻(Cui & Wu, 2018)对公共事务知识获取的正向影响。媒体报道同样可以提升公民的算法知识水平,新闻媒介和社交媒介建构人工智能的话语(Zeng et al., 2022)并影响人们对广义上人工智能技术的感知和态度(Cui & Wu, 2021)。在人际沟通方面,组织心理学将人际沟通作为知识生产的起点,认为“个体通过具有交互性、自反性的沟通实践,能够更好地参与到塑造认知和意义建构的过程中去”(Waddington, 2012:2)。现有研究也证实人们在与账号经营者、亲友等人际沟通过程中获取算法知识的可能性。Bishop(2019)采用线上民族志的方法描绘了YouTube美妆博主如何通过交流共享经验,为组内成员了解算法机制、争夺网络空间的可见性(visibility)提供支持。综上,我们认为算法作为一种热点技术在媒体中有可观的呈现,也成为人际交流中的常见话题。结合知识效果相关研究,媒体报道和人际沟通将帮助用户获取算法知识。由于二者属于获取算法知识的外部渠道,因此将其归为外生因素,并提出如下假设:
H2a:媒体报道会显著正向影响用户的算法知识水平/算法自我效能。
H2b:人际沟通会显著正向影响用户的算法知识水平/算法自我效能。
与外生因素相对,内生因素是用户直接通过媒介使用获取算法相关知识。受制于技术公司对商业机密的保护,外界很难了解平台的运作机制。在这种情况下,用户的媒介使用就成为他们理解和认知算法的重要途径。不少研究者提出作为“经验技术”(experience technology)的算法知识(Blank & Dutton, 2012;Dutton & Shepherd, 2006;Cotter & Reisdorf, 2020),认为用户能够在平台的使用经验中窥探技术逻辑,加深对算法的认知。Eslami等人(2015)进一步将媒介使用分为消极媒介使用和积极媒介使用,认为两者均可提升用户的算法知识水平。参照这一划分方式,我们将注册时长归为消极媒介使用,注册时长仅反映了用户对平台的使用年限,不包含用户的主动使用行为。Eslami等人(2015)认为,注册时间越长,用户越有可能在使用过程中掌握算法的运作规律。此外,本研究将出错率遭际也纳入消极媒介使用范畴。出错率遭际是用户遭遇算法平台意外推荐的频率,它是用户被动经历算法的错误推荐,行为主体为算法平台而非用户。Bucher(2017)通过对25名Facebook用户的深度访谈发现,平台的错误推荐能有效提示用户算法的存在及其操纵行为,从而提升用户的算法认知。综上,本研究对消极媒介使用提出如下假设:
H3a:注册时长会显著正向影响用户的算法知识水平/算法自我效能。
H3b:出错率遭际会显著正向影响用户的算法知识水平/算法自我效能。
在积极媒介使用方面,我们将使用频率、好友数量、账号订阅数、用户卷入度(user engagement)和算法编辑能力这5个更具用户主观能动性的使用行为纳入积极媒介使用范畴。Cotter和Reisdorf(2020)发现,对搜索引擎的使用频率越高,用户越有可能从日常网络体验中学习和了解算法。好友数量是用户主动寻求社交的结果,反映了用户用于拓展人脉、维系情感的主观意愿与努力程度。Eslami等人(2015)认为,用户的好友数量越多,越容易感知部分好友被排除或按不同权重呈现,因此对算法的感知能力也越强。在对40名Facebook用户进行对比分析后,Eslami等人(2015)发现账号订阅数和算法编辑能力(如找出“信息流”中折叠的好友内容、按重要性而非时序对内容重新排序)与用户的算法意识存在正相关性。一些针对算法行动主义者(algorithmic activists)(Velkova & Kaun, 2019)、网店经营者(Klawitter & Hargittai, 2018)和社交媒体博主(Cotter, 2019)等深谙算法逻辑的“数字玩工”(digital playworkers)的研究也表明,那些算法编辑能力强、用户卷入度高的使用者往往具备更高的算法知识和自我效能感。综上,本研究对积极媒介使用提出如下假设:
H4a:使用频率会显著正向影响用户的算法知识水平/算法自我效能。
H4b:好友数量会显著正向影响用户的算法知识水平/算法自我效能。
H4c:账号订阅数会显著正向影响用户的算法知识水平/算法自我效能。
H4d:用户卷入度会显著正向影响其算法知识水平/算法自我效能。
H4e:算法编辑能力会显著正向影响用户的算法知识水平/算法自我效能。
长期以来,学者将媒体报道和人际沟通视为影响知识沟的外生因素。在媒体报道方面,Eveland和Scheufele(2000)发现,在政治知识获取过程中,报纸由于其内容和结构的复杂性,更易扩大公众间的知识沟。Neuman等人(1992:78-79)认为,电视新闻内容的生动易获性,可显著提升低学历群体的知识水平,从而缩小知识差距。在人际沟通方面,Tichenor等人(1970)证实了高SES个体更倾向和其他高SES个体沟通,且交谈内容有利于知识增长;而低SES个体更倾向和其他低SES个体交谈,交谈内容无助于知识增长。Ho(2012)在考察人们对H1N1流行性感冒的认知时发现,人际沟通有助于缩小知识沟。由此可见,现有研究未能就媒体报道和人际沟通是否缩小或扩大知识沟达成共识。鉴于此,本研究提出如下研究问题:
RQ1:外生因素(媒体报道和人际沟通)是否会调节SES对算法知识和算法自我效能的影响?
除外生因素,本研究还将考察内生因素(注册时长、使用频率、用户卷入度、出错率遭际)对算法知识沟的影响。根据经典知识沟理论,高SES群体对知识的接受速率和理解能力要优于低SES群体(Tichenor et al., 1970),因此推测当投入更多时间精力使用算法应用时,高SES群体更容易在媒介使用中发现和感知算法的运作规律,两群体间的算法知识沟将呈现扩大趋势。但随着移动互联网的普及下沉,算法平台的使用方式简化、使用门槛降低,信息形式更加丰富且通俗。当不同群体的媒介渗透率和使用率都趋向高位时,媒介使用模态对不同群体知识获取的作用机制可能发生改变甚至逆转。根据政治学习的MOA(Motivation, Opportunity, and Ability)模型(Luksin, 1990),动机、机遇和能力会影响人们的知识获取。频繁使用算法应用大大增加了低SES群体接触算法的机会,可能也增加了他们更加主动了解算法的动机。因此,使用算法应用的不同模态可能对不同SES群体的算法知识产生差异性影响。据此,我们提出本研究的最后一个研究问题:
RQ2:内生因素(注册时长、使用频率、用户卷入度、出错率遭际)是否会调节SES对算法知识和算法自我效能的影响?
二、研究方法
1.数据与样本
本研究的数据来自网络调查平台问卷星。问卷中我们测量了受访者使用视频类、新闻类和购物类应用过程中的算法经验。在正式问卷调查前,完成一轮预测试(N=113)。在正式调查中,删去答题时间过长或过短的问卷,最终收获有效问卷771份。在所有受访者中,男性占43.5%,女性占56.5%。受访者的年龄中位数组别为“26—35岁”,受教育程度中位数为“大学本科”,月收入中位数区间为“8001—10000元”。由于网络调查触达群体以及本次调查主题(算法知识)的特殊性,该样本与中国全体网民的人口统计结构有所偏差。据受访者背景信息显示,我们所调查的群体并非一般意义的网络用户,而更集中于教育程度中上、中高等收入为主的青年群体。结合网络问卷的IP地理信息,本研究的受访者较为接近日常话语中的“都市青年”或“城市新中产群体”。该群体对互联网技术掌握较好,对新兴技术较为敏感,也更乐于接受新技术,是各类算法应用的主流用户和重要市场目标。
2.测量
(1)因变量:算法知识与算法自我效能
由于算法技术的迭代性和非公开性,目前针对算法知识的测量尚未形成公认的操作范式。本研究在借鉴Cotter和Reisdorf(2020)就搜索引擎提出的“算法知识量表”基础上,修改部分题项,使之成为可适用于各类不同平台的算法知识测量量表(见附录表A1)。受访者对量表中的12项因素分别在多大程度上影响算法应用的推荐结果作判断(采用五级量表测量,1=没有影响,5=强烈影响),得分越高,算法知识水平越高。受访者的算法知识得分为12项因素的平均值(Cronbach’s alpha=.71,m=3.67,sd=.49)。
如果算法知识考察的是受访者对算法理解与认知的客观判断,那么算法自我效能则考察了受访者对自身算法知识能力的主观评价。在Matthew和Eastin(2020)的“网络自我效能量表”基础上,本研究发展出由7道题组成的“算法自我效能量表”。受访者将结合自身经验,对“我能理解关于算法的概念与术语”、“我能够利用算法获取我想要的信息”等说法作判断(采用五级量表测量,1=非常不同意,5=非常同意),得分越高,算法自我效能越高。受访者的算法自我效能得分为7道题的平均值(Cronbach’s alpha=.79,m=3.44,sd=.67)。
(2)外生因素
本研究需要测量的外生因素包括媒体报道和人际沟通。媒体报道涵盖四种媒介:电视、报纸、广播和网络,主要考察受访者通过这四种媒介渠道接收算法相关内容的频率(采用五级量表测量,1=从不,5=经常)。媒体报道得分为四种媒介渠道的平均值(Cronbach’s alpha=.72,m=2.87,sd=.75)。人际沟通测量受访者通过亲友和账号所有者的交谈获取算法相关内容的频率(采用五级量表测量,1=从不,5=经常, m=3.22,sd=1.06)。
(3)内生因素
本研究需要测量的内生因素分为消极媒介使用和积极媒介使用。其中,消极媒介使用包括注册时长和出错率遭际,积极媒介使用包括使用频率、好友数量、订阅数、用户卷入度和算法编辑能力。我们对受访者使用三类算法应用的情况分别进行测量。在陈述中,我们为不同应用类型列举了一些典型案例,以帮助受访者理解。其中,视频类应用的例子包括抖音、快手和哔哩哔哩,新闻类应用的例子包括今日头条、趣头条和天天快报,购物类应用的例子包括淘宝、京东和拼多多。
注册时长和好友数量均采用单一问题,分别询问受访者对三类算法应用的使用年限(采用四级量表测量,1=1年以内,4=10年以上。视频类应用m=2.44, sd=.61;新闻类应用m=1.88,sd=.73;购物类应用m=2.98,sd=.69),以及与受访者相互关注的好友人数(采用五级量表测量,1=10个及以下,5=201个及以上。视频类应用m=2.68,sd=1.15;新闻类应用m=1.69,sd=.93;购物类应用m=2.32,sd=1.11)。
出错率遭际指用户在实际算法应用的使用过程中,遭遇意外或错误推荐情况的频率。我们通过下列4道问题询问如下说法在多大程度上符合受访者的情况:1.平台会向我推送垃圾广告信息;2.某些推送内容使我感到个人隐私被窥探;3.当我不小心点击某个内容,平台会向我推荐更多类似内容;4.平台会莫名其妙地向我推送一些内容(采用五级量表测量,1=非常不符合,5=非常符合)。三类算法应用的出错率遭际为上述四道题目得分均值:视频类应用(Cronbach’s alpha=.72, m=3.49, sd=.76)、新闻类应用(Cronbach’s alpha=.78, m=3.54, sd=.81)和购物类应用(Cronbach’s alpha=.70, m=3.67, sd=.76)。
使用频率和订阅数的测量分别通过一道题询问受访者对三类算法应用的使用频率(采用五级量表测量,1=从不,5=总是。视频类应用m=4.28, sd=.84;新闻类应用m=3.08,sd=1.11;购物类应用m=4.11,sd=.83)和账号的订阅数量(采用五级量表,1=10个及以下,5=201个及以上。视频类应用m=3.03, sd=1.20;新闻类应用m=1.94,sd=1.06;购物类应用m=2.69, sd=1.18)。
用户卷入指用户积极参与各类显著促进使用者与平台内容互动的方式(Oh et al., 2015),它反映了受访者对平台功能的参与情况。本研究综合Xu等人(2018)和Oh等人(2015)提出的“用户卷入度量表”,根据不同算法应用的特征形成新的用户卷入度量表。我们询问受访者对下列功能的使用频率:1.我会收藏某条内容;2.我会转发和分享某条内容;3.我会点赞他人发布的内容;4.我会评论他人发布的内容;5.我会向他人推荐该应用;6.未来我会再次登录该应用(采用五级量表测量,1=几乎不,5=总是)。视频类应用(Cronbach’s alpha=.75, m=3.68, sd=.69)和新闻类应用(Cronbach’s alpha=.84, m=3.08, sd=.86)的用户卷入度分别为受访者就两类平台对上述题目作答的均值。
由于购物类应用的功能设置与视频类和新闻类应用有所不同,因此用户对购物类应用各项功能的参与维度也就与其他两个平台不同。本研究通过询问受访者对下列功能的使用频率:1.我会收藏某件商品;2.我会复制商品链接,转发分享给他人;3.我会评价某件商品;4.我会向客服咨询商品的相关问题;5.我会进入商品直播间;6.我会向他人推荐该应用;7.未来我会再次登录该应用(采用五级量表测量,1=几乎不,5=总是),获取购物类应用的用户卷入度(Cronbach’s alpha=.74, m=3.75, sd=.62)。
算法编辑能力是用户通过干预算法以达到控制内容呈现的一种技术能力。在操作上,我们询问受访者在使用三类算法应用时是否“会设置和调整,让平台推送更符合我的需求”(采用五级量表测量,1=非常不符合,5=非常符合。视频类应用m=3.65, sd=1.03;新闻类应用m=3.39, sd=1.09;购物类应用m=3.71, sd=1.03)。
(4)控制变量
本研究包含若干控制变量:性别、年龄、学历(1=初中及以下,2=高中/中专/技校,3=大专,4=大学本科,5=硕士及以上)、收入(1=每月3000元及以下,2=每月3001-5000元,3=每月5001—8000元,4=每月8001—10000元,5=每月10001—15000元,6=每月15001-20000元,7=每月20001元及以上)。社会经济地位(SES)是本研究的核心变量之一。在不同的研究中,学者通常将教育水平或经济状况,或综合教育水平和经济状况双重因素作为反映个体社会经济地位的重要指标。在本研究中,我们主要选取学历作为衡量受访者SES的变量。
3.模型设定
为验证假设H1—H4e,本研究对视频类、新闻类和购物类这三类算法应用分别建立OLS回归模型。算法知识和算法自我效能为因变量,主要自变量包括SES、外生因素、内生因素以及其他人口学变量。为回答研究问题RQ1和RQ2,本研究在主效应模型的基础上增加SES与外生因素(媒体报道、人际沟通)和内生因素(注册时长、使用频率、用户卷入度、出错率遭际)的交互项,并分析其对因变量的影响。
三、研究发现
本节首先呈现主要变量的描述统计,并使用t检验进行比较(表1 表1见本期第77页)。结果显示,受访者通过人际沟通获取算法知识的频率均值要高于通过媒体报道获取算法知识的频率均值。受访者算法自我效能的平均得分低于其算法知识水平的平均值。配对样本t检验显示,受访者的算法知识水平显著高于其算法自我效能(t=-9.17,p<.001),说明受访者实际对算法知识的客观掌握情况要优于他们对自身算法知识能力的主观评估。独立样本t检验显示,男性与女性受访者在算法知识获取渠道、算法自我效能和算法知识水平上均没有显著差异。
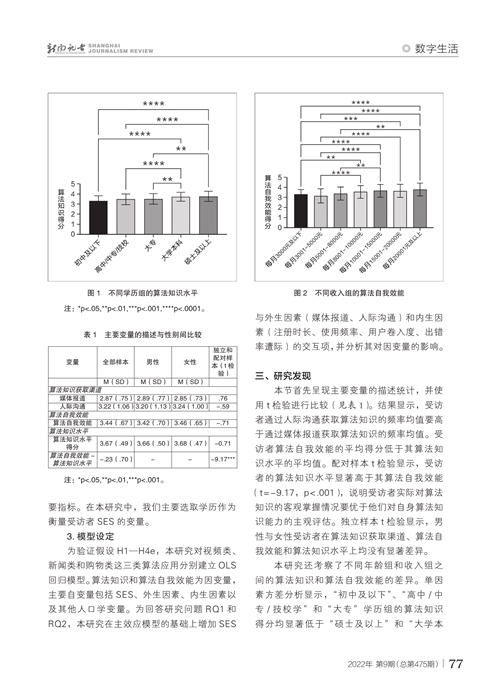
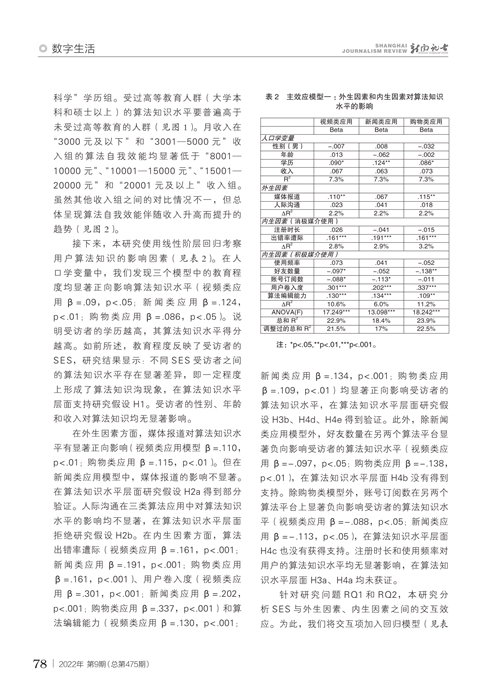
本研究还考察了不同年龄组和收入组之间的算法知识和算法自我效能的差异。单因素方差分析显示,“初中及以下”、“高中/中专/技校学”和“大专”学历组的算法知识得分均显著低于“硕士及以上”和“大学本科学”学历组。受过高等教育人群(大学本科和硕士以上)的算法知识水平要普遍高于未受过高等教育的人群(图1 图1见本期第77页)。月收入在“3000元及以下”和“3001—5000元”收入组的算法自我效能均显著低于“8001—10000元”、“10001—15000元”、“15001—20000元”和“20001元及以上”收入组。虽然其他收入组之间的对比情况不一,但总体呈现算法自我效能伴随收入升高而提升的趋势(图2 图2见本期第77页)。
接下来,本研究使用线性阶层回归考察用户算法知识的影响因素(表2 表2见本期第78页)。在人口学变量中,我们发现三个模型中的教育程度均显著正向影响算法知识水平(视频类应用β=.09,p<.05;新闻类应用β=.124,p<.01;购物类应用β=.086,p<.05)。说明受访者的学历越高,其算法知识水平得分越高。如前所述,教育程度反映了受访者的SES,研究结果显示:不同SES受访者之间的算法知识水平存在显著差异,即一定程度上形成了算法知识沟现象,在算法知识水平层面支持研究假设H1。受访者的性别、年龄和收入对算法知识均无显著影响。
在外生因素方面,媒体报道对算法知识水平有显著正向影响(视频类应用模型β=.110,p<.01;购物类应用β=.115,p<.01)。但在新闻类应用模型中,媒体报道的影响不显著。在算法知识水平层面研究假设H2a得到部分验证。人际沟通在三类算法应用中对算法知识水平的影响均不显著,在算法知识水平层面拒绝研究假设H2b。在内生因素方面,算法出错率遭际(视频类应用β=.161,p<.001;新闻类应用β=.191,p<.001;购物类应用β=.161,p<.001)、用户卷入度(视频类应用β=.301,p<.001;新闻类应用β=.202,p<.001;购物类应用β=.337,p<.001)和算法编辑能力(视频类应用β=.130,p<.001;新闻类应用β=.134,p<.001;购物类应用β=.109,p<.01)均显著正向影响受访者的算法知识水平,在算法知识水平层面研究假设H3b、H4d、H4e得到验证。此外,除新闻类应用模型外,好友数量在另两个算法平台显著负向影响受访者的算法知识水平(视频类应用β=-.097,p<.05;购物类应用β=-.138,p<.01),在算法知识水平层面H4b没有得到支持。除购物类模型外,账号订阅数在另两个算法平台上显著负向影响受访者的算法知识水平(视频类应用β=-.088,p<.05;新闻类应用β=-.113,p<.05),在算法知识水平层面H4c也没有获得支持。注册时长和使用频率对用户的算法知识水平均无显著影响,在算法知识水平层面H3a、H4a均未获证。
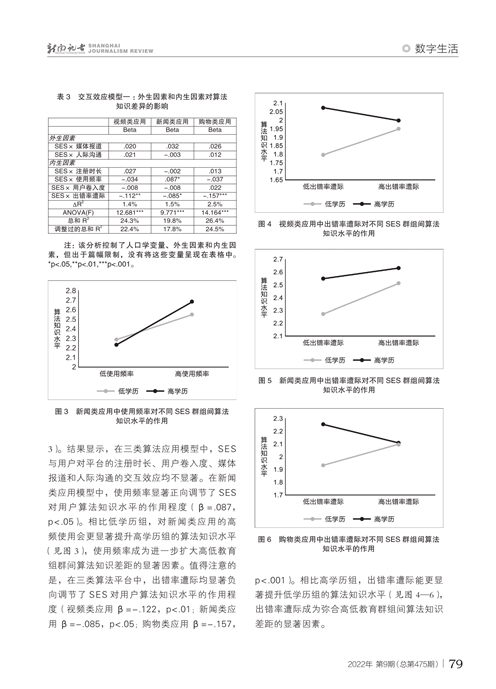
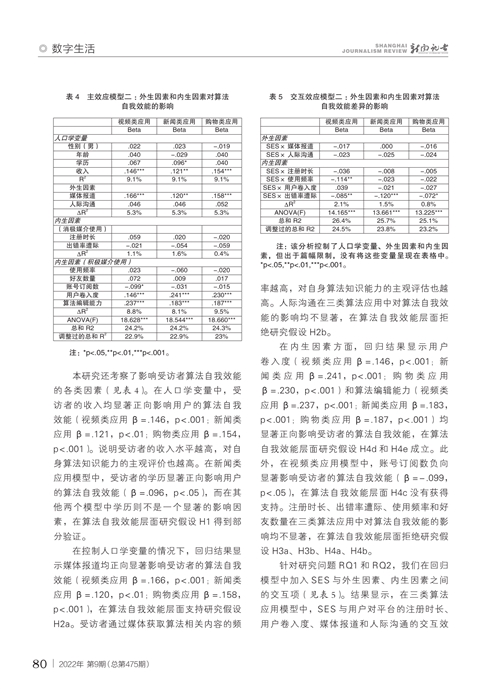
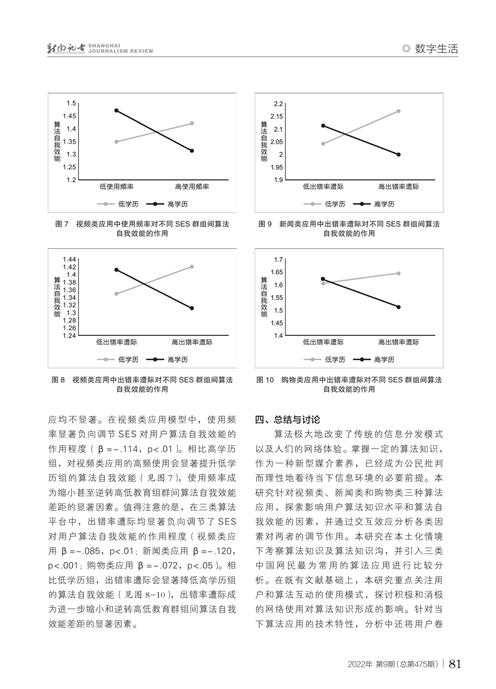
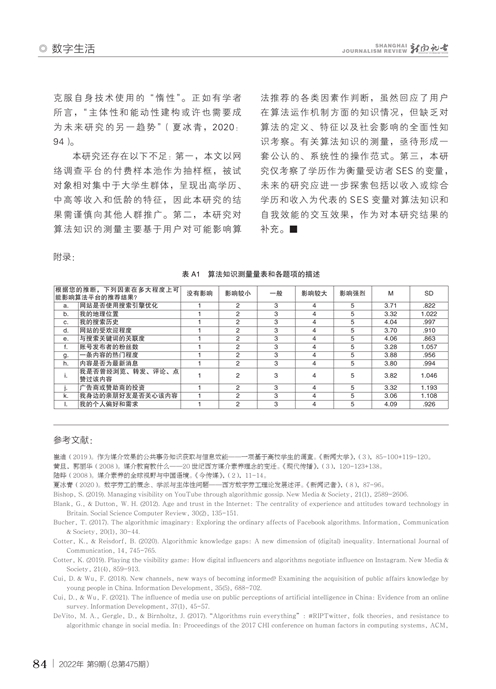
针对研究问题RQ1和RQ2,本研究分析SES与外生因素、内生因素之间的交互效应。为此,我们将交互项加入回归模型(见表3)。结果显示,在三类算法应用模型中,SES与用户对平台的注册时长、用户卷入度、媒体报道和人际沟通的交互效应均不显著。在新闻类应用模型中,使用频率显著正向调节了SES对用户算法知识水平的作用程度(β=.087,p<.05)。相比低学历组,对新闻类应用的高频使用会更显著提升高学历组的算法知识水平(图3 图3见本期第79页),使用频率成为进一步扩大高低教育组群间算法知识差距的显著因素。值得注意的是,在三类算法平台中,出错率遭际均显著负向调节了SES对用户算法知识水平的作用程度(视频类应用β=-.122,p<.01;新闻类应用β=-.085,p<.05;购物类应用β=-.157,p<.001)。相比高学历组,出错率遭际能更显著提升低学历组的算法知识水平(图4—6 图4—6见本期第79页),出错率遭际成为弥合高低教育群组间算法知识差距的显著因素。
本研究还考察了影响受访者算法自我效能的各类因素(见表4)。在人口学变量中,受访者的收入均显著正向影响用户的算法自我效能(视频类应用β=.146,p<.001;新闻类应用β=.121,p<.01;购物类应用β=.154,p<.001)。说明受访者的收入水平越高,对自身算法知识能力的主观评价也越高。在新闻类应用模型中,受访者的学历显著正向影响用户的算法自我效能(β=.096,p<.05),而在其他两个模型中学历则不是一个显著的影响因素,在算法自我效能层面研究假设H1得到部分验证。
在控制人口学变量的情况下,回归结果显示媒体报道均正向显著影响受访者的算法自我效能(视频类应用β=.166,p<.001;新闻类应用β=.120,p<.01;购物类应用β=.158,p<.001),在算法自我效能层面支持研究假设H2a。受访者通过媒体获取算法相关内容的频率越高,对自身算法知识能力的主观评估也越高。人际沟通在三类算法应用中对算法自我效能的影响均不显著,在算法自我效能层面拒绝研究假设H2b。
在内生因素方面,回归结果显示用户卷入度(视频类应用β=.146,p<.001;新闻类应用β=.241,p<.001;购物类应用β=.230,p<.001)和算法编辑能力(视频类应用β=.237,p<.001;新闻类应用β=.183,p<.001;购物类应用β=.187,p<.001)均显著正向影响受访者的算法自我效能,在算法自我效能层面研究假设H4d和H4e成立。此外,在视频类应用模型中,账号订阅数负向显著影响受访者的算法自我效能(β=-.099,p<.05),在算法自我效能层面H4c没有获得支持。注册时长、出错率遭际、使用频率和好友数量在三类算法应用中对算法自我效能的影响均不显著,在算法自我效能层面拒绝研究假设H3a、H3b、H4a、H4b。
针对研究问题RQ1和RQ2,我们在回归模型中加入SES与外生因素、内生因素之间的交互项(见表5)。结果显示,在三类算法应用模型中,SES与用户对平台的注册时长、用户卷入度、媒体报道和人际沟通的交互效应均不显著。在视频类应用模型中,使用频率显著负向调节SES对用户算法自我效能的作用程度(β=-.114,p<.01)。相比高学历组,对视频类应用的高频使用会显著提升低学历组的算法自我效能(见图7),使用频率成为缩小甚至逆转高低教育组群间算法自我效能差距的显著因素。值得注意的是,在三类算法平台中,出错率遭际均显著负向调节了SES对用户算法自我效能的作用程度(视频类应用β=-.085,p<.01;新闻类应用β=-.120,p<.001;购物类应用β=-.072,p<.05)。相比低学历组,出错率遭际会显著降低高学历组的算法自我效能(见图8-10),出错率遭际成为进一步缩小和逆转高低教育群组间算法自我效能差距的显著因素。
四、总结与讨论
算法极大地改变了传统的信息分发模式以及人们的网络体验。掌握一定的算法知识,作为一种新型媒介素养,已经成为公民批判而理性地看待当下信息环境的必要前提。本研究针对视频类、新闻类和购物类三种算法应用,探索影响用户算法知识水平和算法自我效能的因素,并通过交互效应分析各类因素对两者的调节作用。本研究在本土化情境下考察算法知识及算法知识沟,并引入三类中国网民最为常用的算法应用进行比较分析。在既有文献基础上,本研究重点关注用户和算法互动的使用模式,探讨积极和消极的网络使用对算法知识形成的影响。针对当下算法应用的技术特性,分析中还将用户卷入、用户网络规模(好友和订阅数量)和算法编辑能力等多样的媒介使用模态纳入考量。此外,研究深入分析了出错率遭际这一算法情境对算法知识获取的交互影响。尽管从研发角度看,错误推荐是一种技术缺陷,但从用户理解算法的视角出发,这种“缺陷”或为弥合算法知识鸿沟提供了新的可能性。通过以上设计,本研究尝试在分析算法知识沟的基础上,结合用户算法平台的使用行为特征,对算法知识形成机制做更为精确的描述。
首先,本研究证实了不同教育程度的群组之间存在算法知识沟。与经典研究的结论相似,社会经济地位会导致不同群体对知识及新技术掌握方面的差异。算法带来了新的技术体验,但其社会影响可能不是“普惠”的,而是受到既有社会结构的分化。需指出的是,在预测算法自我效能的模型中,学历不再对三类应用模型均有显著影响,反而是收入成为主导因素。我们的推测是,算法知识考量的是用户的客观知识水平,知识的积累往往与教育程度有关,而算法自我效能考察的是用户对自身算法知识掌握能力的自信程度,通常高收入更容易带来个体积极的自我评价。在个体层面上,我们还发现用户实际对算法知识的掌握优于他们对自身算法知识能力的主观评估。算法作为一种新兴技术,可能存在被媒体、社会以及技术公司过分神秘化的倾向,从而导致人们对算法产生较低的自我评价、畏难及不自信的心理。
其次,本研究揭示了一系列影响算法知识的因素。就外生因素而言,新闻媒介一直以来都是公众获取公共事务、科学知识的重要渠道。本研究也确认了新闻媒介在普及算法知识、帮助民众建立算法效能方面的正向作用。近年来,无论从战略方针还是法制建设层面来看,国家都愈发重视对算法平台的监管与治理,强调技术公司的社会责任,大量算法议题开始走进议程设置。这些都为提升用户的算法知识水平和算法自我效能起到积极作用。媒体报道与公共信息教育或可成为未来提升我国公民算法素养的重要手段。就内生因素而言,与以往的研究结论不同,我们发现简单的媒介使用行为并未加深用户的算法认知能力,相反,用户需要主动付出更多的认知努力,调动情绪、充分地利用其技术可供性,才会形成对算法更加深入的理解。此前,有学者考察了使用频率(frequency of use)和使用范围(breadth of use)对算法知识的影响(Cotter & Reisdorf, 2020)。但无论是使用的时长、频率还是范围,上述媒介使用行为都普遍缺乏用户的主体性和能动性,是一种初级的人机交互体验。当工具理性和技术自身的遮蔽性进一步阻碍人们理解和反思算法逻辑及其内嵌于其中的价值标准时,这种简单的媒介使用行为是否还能帮助用户有效揭示算法的运作机理有待商榷。因此,本研究认为作为“经验技术”的算法,更应被放置于用户深度参与技术实践的情境之中——人们正是在与技术“相处”的过程中,通过不断探索与互动,逐渐形成一套掌握技术的认知框架和战术策略。鉴于此,我们将媒介使用行为分为“积极”和“消极”,考察不同的媒介使用方式对算法知识及算法自我效能的影响。研究发现,注册时长和使用频率对两个因变量并无显著作用,提示即便是算法应用的“老用户”甚至“成瘾者”,未必就具备更高的算法知识和自我效能。然而,当用户卷入度越高、算法编辑能力越强时,算法知识得分和对掌握算法知识的自信程度就越高。一方面人们在转评点赞等功能的积极参与过程中,不断根据平台的实时反馈感知算法的运作机制;另一方面通过主动对算法应用的设置与调整,用户获得了一种自主权和操控感。以上两方面都促使用户加深了对算法的认知和自我信念感。与消极媒介使用行为相比,用户积极主动地介入算法应用更能显著提升他们对于算法的感知能力。
有趣的是,出错率遭际与算法知识存在显著的正相关性,但研究未能确认其对算法自我效能有类似的影响。对此我们的解释是,用户在遭遇平台各种“意外”和“尴尬”的内容推荐后,会反思错误出现的原因,或者通过信息检索、与他人讨论等方式寻求解决方案,进而以主动或被动的方式增进对算法的理解。从知识获取的MOA模型来看(Luksin, 1990),出错率遭遇提供了学习的机遇与动机。令人困惑的算法推荐提供了自我反思与批判地看待算法的契机,同时这种困惑与挫败感又促发了用户自我学习、减少不确定性的学习动力。如前文所述,用户对算法知识的实际掌握与他们对算法能力的自我评估可能并不同步。这或许说明,在算法黑箱及技术迷思之下,建立对算法的效能感比实际掌握算法知识更为困难。
最后,本研究还发现在三类应用中,出错率遭际不仅可以有效提高用户的算法知识水平,还成为弥合高低教育群组间算法知识差异、缩小甚至逆转算法自我效能差距的显著因素。换言之,相较于高SES组群,低SES受访者更容易通过算法推荐失效的机会去思考、了解算法技术。这可能是因为高教育程度群体会更加主动地去学习和了解算法(例如通过正式教育或媒体阅读),而低教育程度群体则更需要“出错”的遭际来相对被动地去认知算法。但随着算法技术的更迭与修正,算法出错会越来越少,算法机制将愈发隐蔽并内嵌进网络生存体验,用户可能会弱化对算法本身的思考与批判。从算法素养的应然角度出发,人们应该形成更为积极的姿态去不断理解算法的技术逻辑,参与算法规则的制定过程,争取更大的算法技术透明度,才能规避风险,保护自身利益。
此外,我们还发现了只在某些模型显著的模式:使用频率能有效提升高学历组的算法知识水平且扩大高低教育组群间算法知识差距(新闻类应用);使用频率同时是缩小甚至逆转高低教育组群间算法自我效能差距的因素(视频类应用)。这些发现并不能形成特别一致性的结论,但我们可以推测,获取算法知识与增强算法自我效能存在不同的机制。比如,在日常使用算应用过程中,教育程度较高的群体可能更容易观察、反思、学习,从而切实提高算法知识,但这种反思却未必会增强他们的自我效能。教育程度较低的群体在一般性媒介使用过程中,可能较少形成有效的学习,但频繁地与算法互动可能增强了他们对技术的熟悉感与掌控感,反而正向促进其算法自我效能。
公民在多大程度上理解算法及其运作机制,将塑造人类与算法技术关系的未来走向。我们难以填平个体在社会经济地位上的先天差距,使人们得以站在同一起跑线上接触和认识算法。我们也不能依赖偶尔的“算法失灵”或“算法崩溃”,寄希望于平台出错为公民带来更多的反思机会。因为这些都是相对固化或高度不确定的客观因素。相对上述两条路径,本研究提供了一个更为可行的方案,即从用户主观角度出发,鼓励人们在媒介积极实践中形成关于算法相对专业化、系统化的知识体系。当普通的媒介使用方式不再有效,深度人机交互才能真正帮助人们了解算法运作的规律。这也意味着人的主观能动性对提升个体的算法素养将起到至关重要的作用。因此各类教育机构、基层组织和社会需要思考如何更好地激励公民积极参与平台的各类互动,增进用户了解算法的欲望,克服自身技术使用的“惰性”。正如有学者所言,“主体性和能动性建构或许也需要成为未来研究的另一趋势”(夏冰青,2020:94)。
本研究还存在以下不足:第一,本文以网络调查平台的付费样本池作为抽样框,被试对象相对集中于大学生群体,呈现出高学历、中高等收入和低龄的特征,因此本研究的结果需谨慎向其他人群推广。第二,本研究对算法知识的测量主要基于用户对可能影响算法推荐的各类因素作判断,虽然回应了用户在算法运作机制方面的知识情况,但缺乏对算法的定义、特征以及社会影响的全面性知识考察。有关算法知识的测量,亟待形成一套公认的、系统性的操作范式。第三,本研究仅考察了学历作为衡量受访者SES的变量,未来的研究应进一步探索包括以收入或综合学历和收入为代表的SES变量对算法知识和自我效能的交互效果,作为对本研究结果的补充。■
参考文献:
崔迪(2019)。作为媒介效果的公共事务知识获取与信息效能——一项基于高校学生的调查。《新闻大学》,(3),85-100+119-120。
黄旦,郭丽华(2008)。媒介教育教什么——20世纪西方媒介素养理念的变迁。《现代传播》,(3),120-123+138。
陆晔(2008)。媒介素养的全球视野与中国语境。《今传媒》,(2),11-14。
夏冰青(2020)。数字劳工的概念、学派与主体性问题——西方数字劳工理论发展述评。《新闻记者》,(8),87-96。
BishopS. (2019). Managing visibility on YouTube through algorithmic gossip. New Media & Society21(1)2589-2606.
Blank, G.& Dutton, W. H. (2012). Age and trust in the Internet: The centrality of experience and attitudes toward technology in Britain. Social Science Computer Review, 30(2)135-151.
BucherT. (2017). The algorithmic imaginary: Exploring the ordinary affects of Facebook algorithms. InformationCommunication & Society20(1)30-44.
CotterK.& Reisdorf, B. (2020). Algorithmic knowledge gaps: A new dimension of (digital) inequality. International Journal of Communication14745-765.
CotterK. (2019). Playing the visibility game: How digital influencers and algorithms negotiate influence on Instagram. New Media & Society21(4)859-913.
Cui, D. & Wu, F. (2018). New channels, new ways of becoming informed? Examining the acquisition of public affairs knowledge by young people in China. Information Development35(5)688-702.
Cui, D.& Wu, F. (2021). The influence of media use on public perceptions of artificial intelligence in China: Evidence from an online survey. Information Development37(1)45-57.
DeVitoM. A.Gergle, D.& BirnholtzJ. (2017). “Algorithms ruin everything”: #RIPTwitterfolk theories, and resistance to algorithmic change in social media. In: Proceedings of the 2017 CHI conference on human factors in computing systemsACM3163-3174.
DeVitoM. A. (2021). Adaptive folk theorization as a path to algorithmic literacy on changing platforms. In: Proceedings of the ACM on human-computer interaction CSCW2ACM1-38.
Dogruel, L. (2021). Folk theories of algorithmic operations during Internet use: a mixed methods study. The Information Society37(5)287-298.
DuttonW. H.& Shepherd, A. (2006). Trust in the Internet as an experience technology. InformationCommunication & Society9(4)433-451.
EslamiM.RickmanA.VaccaroK.Aleyasen, A.VuongA.Karahalios, K.Hamilton, K.& SandvigC. (2015). I always assumed that I wasn’t really that close to [her]: Reasoning about invisible algorithms in news feeds. In: Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing SystemsACM153-162.
Eveland, W. P.& ScheufeleD. A. (2000). Connecting news media use with gaps in knowledge and participation. Political communication17(3)215-237.
Gillespie, T. (2014). The relevance of algorithms. In: GillespieT.Boczkowski, P. J.& Foot K. A. (Eds. )Media technologies. CambridgeMA: MIT Press167-194.
Goldman E. (2008). Search engine bias and the demise of search engine utopianism. In: Spink A.& Zimmer M. (Eds. )Information Science and Knowledge Management. Berlin: Springer, 121-133.
GranA.BoothP.& Bucher, T. (2020). To be or not to be algorithm aware: a question of a new digital divide? InformationCommunication & Society24(12)1779-1796.
GruberJ.HargittaiE.Karaoglu, G.& Brombach, L. (2021). Algorithm awareness as an important internet skill: the case of voice assistants. International Journal of Communication151770-1788.
HoS. (2012). The knowledge gap hypothesis in Singapore: the roles of socioeconomic status, mass mediaand interpersonal discussion on public knowledge of the H1N1 flu pandemic. Mass Communication & Society15(5)695-717.
HoS. S.& ChuahA. S. (2022). Thinking, not talkingpredicts knowledge level: Effects of media attention and reflective integration on public knowledge of nuclear energy. Public Understanding of Science31(5)572-589.
Klawitter, E.& HargittaiE. (2018). “It’s like learning a whole other language”: The role of algorithmic skills in the curation of creative goods. International Journal of Communication(12)3490-3510.
LoV. H.& ChangC. (2006). Knowledge about the Gulf Wars: A theoretical model of learning from the news. The Harvard International Journal of Press/Politics11(3)135-155.
LuskinR. C. (1990). Explaining political sophistication. Political behavior, 12(4)331-361.
Matthew, S. Eastin, M. S. & Larose, R. (2000). Internet Self-Efficacy and the Psychology of the Digital Divide, Journal of Computer-Mediated Communication6(1).
NeumanW. R.Just, M. R.& CriglerA. N. (1992). Common Knowledge: News and the Construction of Political Meaning. ChicagoIL: University of Chicago Press.
OhJ.Bellur, S.& Sundar, S. S. (2015). Clicking, assessingimmersingand sharing: An empirical model of user engagement with interactive media. Communication Research, 45737-763.
Price, V.& Zaller, J. (1993). Who gets the news? Alternative measures of news reception and their implications for research. Public Opinion Quarterly57(2)133-164.
Rader, E.& Gray, R. (2015). Understanding user beliefs about algorithmic curation in the Facebook news feed. In: Proceedings of the 33rd annual ACM conference on human factors in computing systems - CHI ’15. ACM173-182.
Russell, Michael F. (2017). The New Gatekeepers. Journalism Studies20(5)631-648.
Swart, J. (2021). Experiencing algorithms: How young people understand, feel aboutand engage with algorithmic news selection on social media. Social Media + Society7(2)1-11.
TichenorP. J.DonohueG. A.& OlienC. N. (1970). Mass media flow and differential growth in knowledgePublic opinion quarterly34(2)159-170.
van DeursenA. J. A. M.& van Dijk, J. A. G. M. (2010). Measuring Internet skills. International Journal of Human-Computer Interaction26(10)891-916.
van DeursenA. J. A. M.& van Dijk, J. A. G. M. (2014). The digital divide shifts to differences in usage. New Media & Society16(3)507-526.
van DeursenA. J. A. M.& HelsperE. (2015). The third-level digital divide: Who benefits most from being online? In: Robinson L.Cotten S.& Schulz J. (Eds. )Studies in media and communications. Emerald Group Publishing, 29-52.
Velkova, J. & Kaun, A. (2019). Algorithmic resistance: media practices and the politics of repair. InformationCommunication & Society24(4)523-540.
WaddingtonK. (2012). Gossip and Organizations. New York: Routledge.
XuQ.Yu, N.& Song, Y. (2018). User Engagement in Public Discourse on Genetically Modified Organisms: The Role of Opinion Leaders on Social Media. Science Communication40(6)691-717.
ZengJ.Chan, C. H.& SchaferM. S. (2022). Contested Chinese dreams of AI? Public discourse about Artificial intelligence on WeChat and People’s Daily Online. InformationCommunication & Society25(3)319-340.
陈逸君系上海大学新闻传播学院讲师,崔迪系复旦大学新闻学院副教授。本文为上海市教育发展基金会和上海市教育委员会2021年度“晨光计划”资助项目。