潘多拉的魔盒:人工智能训练数据的来源、使用与治理
——面向100位AI开发者的扎根研究
■高泽晋
【本文提要】厘清当前阶段人工智能训练数据在AI开发者端口的来源渠道与使用情态是进一步探讨AI训练数据治理的基础与前提。本研究在扎根理论的指导下,以滚雪球抽样法获得的100位AI开发者为研究对象,通过半结构化访谈结合非正式沟通、现实观察、内部与公开资料搜集等方式获取研究数据并提炼概念与范畴,勾勒出现阶段人工智能训练数据在AI开发者端口的来源渠道与使用情态,主要结论包括:(1)AI开发者群体将经由自行采集、公开数据、爬取数据、第三方购买与模拟产生等不同渠道获取的人工智能训练数据用于数据标注、算法验证等常规用途,但存在猎奇分享、窥探心理等异化用途;(2)AI开发者群体对数据使用边界的心理认知主要包括数据泄露/冒用作假、隐私贩卖/侥幸心理、算法偏见/个人主观、干扰社会事务及心理伤害;(3)个人道德、协议约束、法律担忧与媒介监督等因素警示AI开发者对于数据边界问题保持清醒与冷静;(4)将法律、监管、媒体等哲社制衡方案嵌入到AI开发者的数据来源渠道及操作使用层面,进而寻求创新与伦理间的平衡已成为AI数据治理的关键。
【关键词】人工智能 训练数据 数据来源 使用情态 数据治理
【中图分类号】G201
一、引言
作为人类智慧的“容器”,人工智能(Artificial Intelligence,简称“AI”)在蓬勃发展、创造可观经济效益的同时,也为人类社会带来了一个“不确定的未来”。近年来,AI领域的创新成果不断涌现,激发了开发者们的技术热忱,但也引发了人文社会领域的伦理关怀。特别是在人工智能创新成果产生之前的研究与开发阶段,AI训练数据的使用风险逐渐浮出水面,似乎正在复现着海德尔格关于技术之善恶孪生的忧思(Don Ihde,Russell,1980)。虽然学界已对AI训练数据的伦理风险及其可能引发的负面影响进行过不少思辨与评述,也犀利地指出了某些利益集团对AI训练数据可能存在的不当使用路径,但遗憾的是,学界暂未对AI开发者①这一特殊群体的数据获取与使用环节进行过仔细关切或实证调研。
AI开发者是人工智能训练数据的一线研究与使用者,其在人工智能创新成果产生之前的研究与开发阶段发挥着关键作用。虽暂未有官方机构对AI开发者进行过群体数据统计,但从各大AI开发者平台的注册人数来看,截至目前,AI开发者群体数量已远远超过百万级别——仅华为在2020年9月发布的一站式AI平台中开发者注册人数便已达150万人次,百度飞桨平台中的AI开发者注册数量也已累计达到265万人次。而在全球范围内,类似华为、百度这样的AI开发者平台已超过20家,其中Google AI、OLAMI AI、Microsoft Azure等较为知名的AI开发者平台中更是集聚着数量惊人的AI开发者们。
正是这群已达百万规模集群数量的AI开发者们在日常生活与一线工作中实时获取并操作着被人文社科学者所日夜担忧的巨擘量级AI训练数据。在人工智能技术及应用快速拓展的今天,AI开发者们对算法训练数据的需求日益旺盛。AI开发者们是通过何种方式获取如此海量、多样和实时的AI训练数据的?经由不同途径被获取的AI训练数据正在被开发者们如何使用?回答以上问题,能够清晰地展示当前阶段人工智能训练数据在AI开发者这一重要端口的来源渠道与使用情态,是进一步探讨AI训练数据治理路径的基础与前提。
有鉴于此,本研究在扎根理论的指导下,以滚雪球抽样法获得的100位AI开发者作为研究对象,通过半结构化访谈结合非正式沟通、现实观察、内部与公开资料搜集等方式系统地获得研究数据,运用生成性归纳方法从原始研究数据中提炼概念与范畴,试图勾勒出现阶段人工智能训练数据在AI开发者这一重要端口的来源渠道与使用情态,并对人工智能训练数据的治理路径进行展望,以期为学界、业界提供一项富有参考意义的研究素材。
二、研究的简要回顾
人工智能是一门极富挑战性的学科,其通过模拟、延伸、扩展人的智能进而不断开发出新的理论、方法、技术及应用(Jeavons,Andrew,2017;苏涛,彭兰,2019)。近年来,随着深度学习技术的进步,人工智能在语音识别、图像识别、自然语言处理、人机博弈等领域蓬勃发展(张俊芳,2017)。机器已然能够在这些领域内胜任人类的部分工作,甚至在一些情况下,机器的工作效率与准确率优于人类,这为人类社会中劳动力结构的改善带来希望,也正在历史的长河中雕刻出人类生产、生活方式的巨大转变。作为人类智慧的“容器”,人工智能在蓬勃发展、创造可观经济效益的同时,也为人类社会带来了一个“不确定的未来”。首先,以史蒂芬·霍金为代表的著名科学家们曾对机器的智能化限度发出警告,表达了对于机器智能操控人类这一可能性的担忧(蔡曙山,2020)。学界对此的忧思主要集中于机器从人类手中争夺其自我进化过程的智能奇点论调,也即机器权利争论之学术流派;其次,以劳动力结构转变造成的失业问题为典型代表,人工智能或可对现实社会秩序造成的冲击亦引发了公众疑惑并激发出广泛的社会探讨(高奇琦,张结斌,2017)。此类学术探索多集中于人工智能技术对既有产业的改造及其对新兴业态的造就过程;此外,人工智能对伦理的严峻挑战业已被学界提上人文关怀议程。在这一学术关切领域内,隐私权被侵犯、隐含的算法偏见、对人身或财产安全的威胁以及道德代码等问题均是研讨之重点(Russell et al.,2015;邵国松,黄琪,2017;周程,和鸿鹏,2018)。
事实上,以上关于人工智能不确定性的学术关怀归根结底源自于人工智能学科研究的本质——其发展有赖于使用大量的“人类”数据集,在反复训练算法的过程中使机器不断学习,并最终获得接近于人类的感知智能与行为智能。而这些“人类数据”通常涵盖了图像(人脸、指纹、虹膜等生物特征数据)、声音(声纹识别)、文本(短信、网络通信文本)等关乎隐私与安全的重要信息,并具有海量(volume)、多样(variety)和实时(velocity)这三大性质特征(魏凯,2013)。正因如此,个人数据信息的失控与被窥探之情形得到了较多学术关照。一直以来,由数据泄露所导致的隐私风险、安全风险及政治道德是学界惯常探讨的话题。曾有调研报告显示,2018年3月,Facebook利用平台数据进行算法推送进而诱导美国公民为候选人进行投票成为印刻在历史上的一次人工智能干预政治的社会事件(郭环,2020)。而另外一些平台中用户隐私照片的泄露则很有可能催生侵害性交易,这指向了数据掌控者将碎片化信息提取并用于牟利的行为(孟小峰,王雷霞,刘俊旭,2020)。除此之外,看似“价值无涉”的人工智能算法存在偏见隐藏的可能性,AI开发者们若将偏见隐藏于算法训练的过程之中,将产生深远的社会影响——一个典型的案例是谷歌算法将黑人常用名与偏见性被捕广告相勾连,导致非裔与白人使用谷歌工具时屏幕显示信息的不同(邵国松,黄琪,2019)。
正因如此,在人工智能快速发展的同时,学界也正试图从法律、媒介、哲学或社会科学等其他学科领域寻找平衡AI训练数据负面效应的解决之道。首先,学者们不断在司法裁判与法律条文中摸索人工智能训练数据的边界与底线,第三方民事权益(包括但不限于自然人肖像权、隐私权、个人信息)在人工智能领域的合法性保障被不断提上议程(张明广,2018);其次,将媒介作为AI产业进步与发展的制衡性监督力量是学界对人工智能训练数据隐患的另一条尝试路径。媒介作为独立于行政权、立法权、司法权以外的第四种社会权利(陈力丹,2003;程金福,2010),被用以关切行政与法律层面对AI监管举措的合理性,并对现实中未被提上监管议程的AI应用实践进行挖掘、报道,以引发广泛重视与相关权利部门的回应(郭珂静,张悦晨,2020;王俊秀,2020);此外,在哲学视域下反思机器道德并为人工智能的技术研发在哲学社会科学领域寻找平衡之道亦成为学界关切的重要范畴(Wallach,Allen,Smit,2008)。面对人工智能对既有社会伦理及秩序造成的冲击,学界提出了“数据治理”的重要内涵——从本质上来看,对人工智能训练数据所有权和使用权分离问题的探析即是在关注AI开发者们如何合规地获取和使用训练数据(张保生,2001)。也即,研究AI训练数据的治理需要进一步厘清当前阶段人工智能训练数据在AI开发者这一重要端口的来源渠道与使用情态——AI开发者作为人工智能训练数据的使用者而非所有者,究竟从何获取数据?又将如何使用?
遗憾的是,目前学界对AI训练数据的思辨与探讨暂未以AI开发者为出发基点进行考量,而是跳过人工智能学科中AI开发者这一重要的“基础端口”群体而直接进入“上层建筑”中探讨相关哲思与伦理问题。人工智能训练数据在AI开发者这一重要端口的来源渠道与使用情态尚未被清晰地展示,亦无有力证据支撑,亟需以AI开发者群体为重要观察对象,通过实证研究来系统地回答AI开发者日常一线工作中所需训练数据究竟从哪里来、正在被如何使用等重要问题——这亦是进一步探讨AI训练数据治理路径的基础与前提。
三、研究方法
(一)方法选择与数据来源
本研究选择扎根理论系统地搜集研究所需材料,运用生成性归纳方法从原始研究材料中提炼概念与范畴,从而发现和建立“故事线”(费小冬,2008),试图勾勒现阶段人工智能“训练数据”的来源渠道与使用情态。在数据获取层面,本研究采取滚雪球抽样法,筛选得出100位人工智能一线从业者作为访谈样本,于2019年8月—12月完成半结构化访谈,并结合非正式沟通、现实观察、内部与公开资料等方式获取更为全面的研究基础数据。
值得注意的是,在正式展开半结构化访谈之前的非正式沟通环节,注重观察部分访谈样本与这些随机沟通的受访人员在回应哪些访问内容时容易出现犹豫、迟疑或难以启齿的情形,对此做好预备记录。在正式展开半结构化访谈的过程中,对此类已进入预备记录的访问内容着重关注,并记录正式访谈样本在面对这些访问内容时的回应时间、语气等实际状态。
(二)受访者信息
虽然人工智能的研究与应用领域不断拓展,诸如人脸识别、步态识别、智能语音、陪伴机器人、智能驾驶等应用逐渐丰富(高泽晋,2020),但在AI算法的研发与训练阶段,研究者所需获取的训练数据大多分布于语音、图像、视频与文本素材行列(王立娜,2017)。因此,本研究以语音、图像、文本及视频等AI数据领域为考察入口,并针对这些重要领域进行滚雪球抽样最终获得100位受访者作为研究对象。在征求受访者意见后,本研究对来自上述四大核心AI数据领域的100位受访者进行匿名处理,仅提供受访者编号及其日常接触的训练数据类型进行区分。其中有13人属于面对面访谈,4人属于邮件访谈,17人属于网络访谈(微信/QQ),其余66人采用电话访谈,平均访谈时间为30分钟。
(三)资料编码与饱和度检验
本研究除笔者参与编码外,另行以劳务聘用形式招募三名具备本科学习经历的人员(其中1名为本科大三在读、另2名为本科毕业已工作)共同参与“2+1+4”过程编码模式,即同一份原始资料分别由两人进行开放式编码并经由第三者审核,在编码过程中四人及时交流意见并共同对争议之处进行商议解决,以避免研究者主观判断所致偏见。编码结束后,通过Nvivo软件进行一致性检验,各范畴一致性指数均处于0.876至0.951之间,表明结果具有较好一致性。完成编码全过程后,选取部分受访者进行反馈确认以进一步消除研究者的个人偏见。
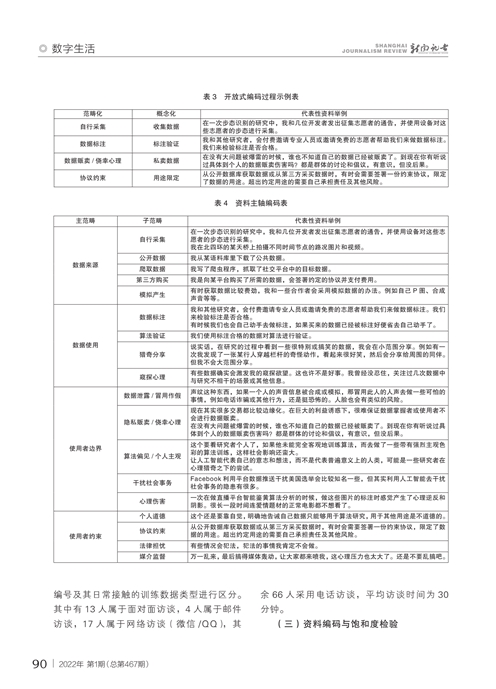
首先,对原始资料进行开放式编码。将打散的原始资料逐句标签,根据标签之间的逻辑生成概念。保留复现频率超过3次的概念,并将相似概念进行范畴化整理。使用Nvivo11软件辅助编码,获得52个初始概念和21个范畴。
其次,通过开放式编码呈现出的相对独立之范畴间的内在关联尚未厘清,因此本文接续根据因果、过程与情境进一步升华业已提取的范畴化概念,提炼出更高一级的主范畴,也即资料主轴编码。通过对资料主轴编码形成共计4个主范畴。
再次,在上述两级资料编码的基础上进行提纲挈领性式选择性编码,提炼出更为核心的范畴,并构建扎根于实证材料的理论解释模型。鉴于核心范畴应当具备核心、解释性、频现及强联系等特质,本研究发现“AI开发者群体对人工智能训练数据的使用行为特征”是其他概念范畴的中心并与各个范畴间链接紧密,对研究具备提纲挈领之作用,故将“AI开发者群体数据使用行为”上升为核心范畴,并基于核心范畴与其他主范畴的交互逻辑初步搭建出“AI开发者群体对人工智能训练数据的使用行为解释模型”。
最后,值得关注的是,上述编码过程以及解释性框架的形成均是依托对所获原始资料总量的95%进行编码而得到,在对相关资料进行概念化和范畴化分析、整理出各级题项并厘清各概念维度与特征之后,利用剩余5%的原始资料进行重复性编码操作与分析,发现在已有概念和范畴的基础上并未产生新的概念范畴与相关关系,因此认为编码操作及解释性构建在理论上已达饱和。
四、结果与讨论
经研究可知,AI开发者群体将经由自行采集、公开数据、爬取数据、第三方购买与模拟产生等不同渠道获取的人工智能训练数据用于数据标注、算法验证等常规用途或猎奇分享、窥探心理等异化用途。而AI开发者群体在日常生活与一线工作过程中触达的风险边缘类型主要包括数据泄露/冒用作假、隐私贩卖/侥幸心理、算法偏见/个人主观、干扰社会事务及心理伤害,但个人道德、协议约束、法律担忧与媒介监督等因素警示AI开发者在使用训练数据时对于数据边界问题保持清醒与冷静。
(一)数据来源:太阳之下的暗礁险滩
经过实证研究可知,当前阶段,AI开发者们获取人工智能训练数据的来源主要有自行采集、从公开数据集获取、使用数据挖掘或爬取技术进行抓取、第三方购买、模拟产生等五种途径。以下将对这五种数据获取途径进行阐述。
第一种,自行采集。例如在志愿者知情的前提下对其进行数据采集,或在公共场景下主动收录或拍摄。
第二种,从公开数据集获取目标数据。MNIST、CIFAR、PASCAL VOC、MS COCO、LSUN、SVHN等较为经典的人工智能公开数据集汇总了人脸、人体姿态、医疗、自然景观、城市等经典数据。这些公开数据集往往来自于AI开发者们的既有研究与贡献。例如哈佛beamandrew机器学习和医学影像研究者在Github中为医疗领域的机器学习研究贡献了许多重要的图片数据。②某些领域的研讨或学术会议也逐渐成为AI训练数据的主要贡献源,ISBI(生物医学成像国际研讨会)将其每届的研究数据无偿贡献于grand-challenge平台中。③
第三种,使用数据挖掘或爬取技术进行抓取。一方面,研究者们利用自身开发的爬虫脚本进行数据摘录与收集。另一方面,市场上萌生出许多便捷易用的爬虫工具,免去了研究者们自行编制爬虫代码的繁琐流程,这些爬虫工具通常需要付费使用。
第四种,第三方购买。AI开发者们在训练算法时面临大量的数据需求,而通过自行采集或爬虫抓取往往需要耗费大量的精力。目前,市场中存在着众多以数据贩卖为经营来源的商业团队,他们向AI开发者们提供有偿数据服务,按照数据类型、数据量或是否需要标注等规则“明码标价”。AI开发者们向这类第三方商业团队采买数据时,有时需要签署一份数据约束协议,用来约束开发者对于数据的使用情景并声明责任风险。除此之外,一些掌握数据挖掘技术的个人在某些商业平台中也公开展示相关业务讯息,表示其能够为数据需求者提供定制化的有偿服务。
第五种,模拟产生。AI开发者们通过常用途径难以获得所需数据类型时,数据模拟的方法被机动使用。研究者们利用先进的图片编辑、视频制作或音频合成手段,制作出训练AI算法所需的仿真数据以供开发。
AI训练数据的获取途径可谓“太阳之下的暗礁险滩”。在中国知网、Web of Science数据库中搜索关于人工智能算法训练的文章,可以发现不少研究者毫不避讳地提及数据的来源与数据训练方法。而在半结构化访谈的过程中,关于AI训练数据的获取方式与数据类型相关话题,受访者亦能自如、开放地谈论。这并非由于受访者对于当前阶段AI训练数据来源的充分自信,而是源于人工智能在当前阶段已成为国家综合实力的重要组成部分,为争夺新一轮新兴技术高地已成为各国AI开发者们的不二选择。事实上,技术开发者们深知在现阶段AI训练数据的来源渠道中,自行采集、从公开数据集获取、模拟产生这三类情形因其充分尊重了数据主体的授权范围而显得较为稳定与合规,而使用数据挖掘或爬取技术的情形由于未保障数据主体的知情权与授权范围而面临着较大的伦理与法律隐患。虽然向第三方购买数据能够将AI开发者获取数据时的相关风险“转嫁”至第三方机构或个人,但第三方机构或个人出于牟利目的而使用的数据采集手段则更加无法控制。尽管如此,多数AI开发者们认为在当前阶段,突破技术难题、解决行业瓶颈是他们的首要任务,并期冀将AI训练数据需求与来源合规性之间的平衡问题交由社会科学领域来解决。
我知道这可能存在一些问题,但目前我在研究开发时确实需要大量数据,算法难题解决后不仅能够为行业带来突破,很多衍生应用也将为社会、经济带来益处。我需要数据,没有另外的选择。但我希望会有技术以外的方式去为我们解决来源合规与技术需要之间的难题。(受访者B6)
(二)数据使用:窥探隐喻与猎奇分享的存在
在厘清当前阶段AI训练数据的来源渠道后,AI训练数据正在被如何使用成为另一个亟需回答的问题。通过访谈可知,AI开发者们在获取训练数据后,常规的做法是对数据进行标注操作,并利用其中被有效标注的部分进行算法验证与机器训练。以上常规数据操作与使用过程为学科发展奠定了重要的前置基础。然而,69%的受访者表示他们曾在获取的训练数据中发现新奇的图片、视频、声音或文本,并在小范围内进行娱乐性分享。例如受访者中存在将其所获取的包含特殊五官的人脸、特异步态信息的图片或视频进行分享与交流的情况。另有49%的受访者则谈及他们曾对训练数据中与正常开发无关的场景或信息产生好奇并进行深度窥探的经历。例如受访者存在将某些直播平台鉴黄算法训练中的不雅图片或包含某些特殊地理信息场景的视频进行深度窥探之情形,亦有部分智能语音算法开发者在触达一些涉私声音时出于好奇亦可能进行辨听。虽然受访者在访谈中均表示这种窥探心理与猎奇分享行为仅为满足自身好奇心或出于娱乐性目的而发生,且均在小范围内扩散,但纵使在未造成重大社会影响的情况下,将AI训练数据用作数据标注、算法开发之外的行径已然触碰数据伦理的“边界”。
事实上,AI开发者群体虽然不是人工智能训练数据的产生源,但却是这些数据最为主要的掌控者与直接使用者。目前的学术讨论在一定程度上忽略了对AI开发者这一群体的行为与心理特征进行考察。在今后的研究中,将AI开发者作为重要的关注群体加以学术考察是十分必要的。
(三)使用者边界:AI开发者如何认知数据边界的触达
作为人工智能训练数据的主要掌控者与直接使用者,AI开发者群体将如何认知数据的使用边界值得探究。在对所获访谈资料进行编码整理后,本研究将AI开发者群体对数据使用边界的认知划分为数据泄露/冒用作假、隐私贩卖/侥幸心理、算法偏见/个人主观、干扰社会事务及心理伤害这五种主要类别。
第一种,数据泄露与冒用作假。AI开发者通常在技术思维惯性下将训练数据的泄露与冒用作假行为相勾连,并认为二者在很大概率上是相伴而生的。在AI开发者的观念中,被泄露的数据很可能被掌握先进技术的人员合成模仿性文件,达到“以假乱真”的效果。
当机器能够用接近于原始声纹特征的方式与人类进行对话、交谈,这可能会导致冒用或犯罪。例如,当你接到一个电话,电话另一边说话的声音、语气竟然与你的某位朋友完全一致或很接近,但实际上正在与你电话交谈的却不是你的朋友,而是被另一群人所操控的机器。(受访者A17)
第二种,隐私贩卖与侥幸心理。利益驱动被认为是产生犯罪心理的基础理论之一(梅传强,王敏,1999:79-82)。在访谈过程中,当被问及“如果有人斥资或提供其他好处向你购买数据,你是否会答应?”这一问题时,仅有14%的受访者立刻、坚定地回答“不会”,其余86%的受访者则在回答该问题时显示出迟疑和停顿,并表达出“应该不会吧”、“要思考下”、“可能”、“也许”等犹豫性答案。这表明,利益的诱惑有可能导致AI开发者触碰数据使用的边界。当进一步向受访者追问其犹豫性回答的原因时,受访者的回应充分显示出其侥幸心理——当前阶段,关于AI训练数据的法律约束并不完备,纵使触碰数据使用的伦理边界,未必会受到相应的法律惩罚,且社会公众虽然已对私人数据的保护有所觉醒,但暂未出现因个人数据泄露而造成的大型社会影响事件,这使得部分AI开发者对数据的使用产生侥幸意识。
第三种,算法偏见与个人主观。在这一层面,AI开发者认为当机器被赋予了某种特定的主观思想时,将会造成潜在的社会隐患或社会伤害。例如开发者按照自身的主观意见与个人偏见去训练机器算法时,机器所展示出的特征或将越过道德底线与法律红线,甚至越过一个社会系统的主流价值观。
第四种,干扰社会事务。72%的受访者主动谈及Facebook利用平台数据推送来干扰美国选举的案例。AI开发者认为,当AI训练数据的特征、结构被使用者清晰地掌握之后,那么使用者便可轻而易举地利用数据来干扰政治、经济、文化或其他领域的社会事务。
第五种,心理伤害。在研究访谈中,个别访谈者谈及AI训练数据对AI开发者的心理影响与伤害问题。当AI开发者面对海量的图片、声音、视频、文本时,某些特殊的信息可能会给AI开发者造成负面心理影响。一位受访者表示,其所在的机构为治理网络直播环境制定了开发人工智能鉴黄算法的任务,这需要AI开发者使用大量的色情数据对算法进行训练,以提高机器识别的准确率。该位受访者因在短期内处理了大量的色情数据,导致其在完成这项任务后相当长的一段时间内对于正常爱情题材的影视作品都相当排斥。事实上,人工智能算法在识别罪犯、警报异常、处理违规事件方面拥有着强大的能量,在这些应用场景的开发过程中,AI开发者不得不面对大量负面数据,但却被忽视了应有的积极心理建设。
(四)使用者约束:道德、协议、法律、媒介的边界控制
通常情况下,AI训练数据会被研究者用于数据标注或算法验证,但人类猎奇分享与窥探心理的存在可能使得AI开发者们在一些特殊情形下丧失数据边界意识。通过访谈可知,目前阶段对AI开发者产生心理震慑作用的四个主要制衡因素分别是个人道德、协议约束、法律担忧与媒介监督,这些因素警醒AI训练数据的一线使用者对于数据边界问题保持冷静与清醒。
其中,个人道德是指用来指导个人行为是否符合道德标准的一种观念,作为一种社会意识形态,道德具有一种无形的强大力量(周宏,1999)。个人道德通过对AI训练数据的使用者进行积极心理暗示,使之产生不逾数据边界的主动心理特征。而协议约束则是指AI开发者们在获取数据时,与数据主体、开放数据库或第三方商业机构签署的数据使用协议,协议中明确规定了数据使用范畴与风险责任承担。虽然AI行业的法律约束在当前阶段并不完备,在一些边缘情况下试探数据红线未必会受到相应的法律惩罚,进而使部分数据使用者产生侥幸心理,但是对触犯法律与强制性处罚的担忧依然在很大程度上规范着数据使用者的行为。此外,对媒介监督或可导致的舆论风险亦对数据使用者起到了行为与心理的有效监督。
五、结论与展望
(一)结论:将AI开发者群体作为考量基点
本研究以AI开发者为出发基点进行考量,在扎根理论的指导下,勾勒出现阶段人工智能训练数据在AI开发者这一重要端口的来源渠道与使用情态。本研究所获主要结论如下:(1)当前阶段,AI开发者们获取人工智能训练数据的来源主要有自行采集、从公开数据集获取、使用数据挖掘或爬取技术进行抓取、第三方购买、模拟产生等五种途径。其中,自行采集、从公开数据集获取、模拟产生这三类情形因其充分尊重了数据主体的授权范围而显得较为稳定与合规,使用数据挖掘或爬取技术的情形由于未保障数据主体的知情权与授权范围而面临着较大的伦理与法律隐患。虽然向第三方购买数据能够将AI开发者获取数据时的相关风险“转嫁”至第三方机构或个人,但第三方机构或个人出于牟利目的而使用的数据采集手段则更加无法控制。尽管如此,多数AI开发者们认为在当前阶段,突破技术难题、解决行业瓶颈是他们的首要任务,并期冀将AI训练数据需求与来源合规性之间的平衡问题交由社会科学领域来解决;(2)AI开发者们通常将获取的训练数据用于标注或算法验证,但存在窥探隐喻与猎奇分享之行为。AI开发者虽然不是人工智能训练数据的产生源,但却是这些数据最为主要的掌控者与直接使用者。目前的学术讨论在一定程度上忽略了对AI开发者这一群体的行为与心理特征进行考察;(3)AI开发者群体对数据使用边界的认知主要划分为数据泄露/冒用作假、隐私贩卖/侥幸心理、算法偏见/个人主观、干扰社会事务及心理伤害;(4)个人道德、协议约束、法律担忧与媒介监督等因素警示AI训练数据的一线使用者对于数据边界问题保持冷静与清醒。
(二)展望:数据治理需寻求创新与伦理平衡
当前阶段,中国、美国与欧洲是全球人工智能的主要玩家。对于AI训练数据的治理,各国亦有着不同的思考与路径。欧盟对于立法和监管非常重视,与时俱进地建立与人工智能发展相适配的法律框架是欧盟发展AI战略的重要支柱(曹建峰,方龄曼,2019)。而美国则采取了轻监管、促创新的路径,秉承着政策不能阻碍AI发展、降低创新门槛与成本的原则,采取渐进式的监管来逐一应对新出现的具体问题。④中国则提倡“科技向善”的AI数据治理观点,2019年6月17日中国新一代人工智能治理专业委员会公开发布了《新一代人工智能治理原则——发展负责任的人工智能》,⑤提出了人工智能治理的框架和行动指南,旨在号召人工智能发展相关各方在遵循和谐友好、公平公正、包容共享、尊重隐私、安全可控、共担责任、开放协作、敏捷治理的原则下共同促进新一代人工智能的健康发展(中国新一代人工智能治理专业委员会,2019)。而在2021年9月1日,《中华人民共和国数据安全法》正式开始推行,将包括人工智能训练数据在内的数据安全问题正式提至国家监管议程,表明了中国坚持维护科技伦理与数据向善的决心(国家图书馆研究院,2021)。综观各国对AI训练数据的治理路径,大都包含了完善法律法规、健全伦理体系、强化媒体监督等核心内涵。
鉴于人工智能“数据治理”的内涵即是对AI训练数据所有权和使用权分离问题进行探析,那么将法律、监管、媒体等制衡方案嵌入作为人工智能训练数据的使用者而非所有者——AI开发者群体的数据来源渠道与操作使用层面,针对不同的数据来源渠道与数据操作去向进行具体制衡设计,并根据AI开发者群体的边界触达特征与边界约束条件不断寻求创新与伦理间的平衡,已成为目前各国对于促进AI产业良性发展、有效治理AI训练数据的关键所在。■
注释:
①“AI开发者”是指在一线工作中直接使用AI训练数据进行技术开发、应用开发与产品工程化的人群。值得注意的是,本文所指的AI开发者与数据安全领域的“数据控制者”概念不同,虽然AI开发者与数据控制者均有有权对个人有效数据进行处理,都可被看作是数据的处理方,但是数据控制者具备决定个人数据被处理的目的和方式之权利,而AI开发者原则上应当在数据控制者的既定规则与指令之下使用相关数据。但作为AI训练数据的直接接触、使用者,AI开发者群体对数据的使用情形亦可能出现失控进而引发潜在风险。本研究重点关注已达百万级别的AI开发者人群在一线获取、使用人工智能训练数据的实际情况。
②哈佛大学beamandrew机器学习和医学影像研究者在Github中为医疗领域的机器学习研究贡献的图片数据库“Medical Data for Machine Learning”,进入链接 https://github.com/beamandrew/medical-data可查。
③生物医学成像国际研讨会ISBI将其每届的研究数据无偿贡献于 grand-challenge平台“Grand Challenge:A platform for end-to-end development of machine learning solutions in biomedical imaging”,进入链接https://grand-challenge.org/All_Challenges/可查。
④腾讯研究院在2020年2月6日发布的网络报告《2019年全球人工智能治理报告:从科技中心主义到科技人文协作》,进入链接https://mp.weixin.qq.com/s/lgB1-gcArjoZwObuf6hW1g可查。
⑤中国新一代人工智能治理专业委员会在2019年6月17日发布的网络报告《新一代人工智能治理原则——发展负责任的人工智能》,进入链接http://www.most.gov.cn/kjbgz/201906/t20190617_147107.html可查。
参考文献:
蔡曙山(2020)。生命进化与人工智能——对生命3.0的质疑。《上海师范大学学报(哲学社会科学版)》,(3),83-99。
曹建峰,方龄曼(2019)。欧盟人工智能伦理与治理的路径及启示。《人工智能》,(4),39-47。
陈金福(2010)。当代中国媒介权力与政治权力的结构变迁——一种政治社会学的分析。《新闻大学》,(3),22-29。
陈力丹(2003)。“第四权力”。《新闻传播》,(3),12-13。
费小冬(2008)。扎根理论研究方法论:要素,研究程序和评判标准。《公共行政评论》,(3),23-43。
高奇琦,张结斌(2017)。社会补偿与个人适应:人工智能时代失业问题的两种解决。《江西社会科学》,(10),25-34。
高泽晋(2020)。创新扩散视角下对百度apollo智能驾驶开放平台的观察与研究。《中国科技论坛》,(11),147-152。
郭环(2020)。社交媒体时代的美国政治投票解析。《青年记者》,(26),33-34。
郭珂静,张悦晨(2020)。“赛托邦”与“赛维坦”:人工智能的媒介呈现——以人民日报与纽约时报的报道为例。《青年记者》,(14),33-34。
国家图书馆研究院(2021)。《中华人民共和国数据安全法》将于9月1日起施行。《国家图书馆学刊》,(4),63-63。
梅传强,王敏(1999)。《犯罪心理学》。北京:中国法制出版社。
孟小峰,王雷霞,刘俊旭(2020)。人工智能时代的数据隐私、垄断与公平。《大数据》,(1),35-46。
邵国松,黄琪(2017)。人工智能中的隐私保护问题。《现代传播(中国传媒大学学报)》,(12),1-5。
邵国松,黄琪(2019)。算法伤害和解释权。《国际新闻界》,(12),27-43。
苏涛,彭兰(2019)。 反思与展望:赛博格时代的传播图景——2018年新媒体研究综述。《国际新闻界》,(1),41-57。
王俊秀(2020)。数字社会中的隐私重塑——以“人脸识别”为例。《探索与争鸣》,(2),80-90。
王立娜(2017)。美国计算机社区联盟发布白皮书明确人工智能六大待挖掘领域。《世界科技研究与发展》,(2),197-197。
魏凯(2013)。大数据的技术挑战及发展趋势。《信息通信技术》,(6),22-27。
张保生(2001)。人工智能法律系统的法理学思考。《法学评论》,(5),11-21。
张俊芳(2017)。人工智能产业发展及全球化资源配置研究。《中国软科学》,(S1),131-141。
张明广(2018)。《人工智能时代整合化个人信息的隐私权保护》。武汉,华中师范大学。
周程,和鸿鹏(2018)。人工智能带来的伦理与社会挑战。《人民论坛》,(2),26-28。
周宏(1999)。道德标准与标准之标准。《道德与文明》,(1),9-10。
Don Ihde, Allan M. Russell. (1980). Technics and praxis: a philosophy of technology. American Journal of Physics48(3)259-259.
Jeavons, Andrew (2017). What Is Artificial Intelligence?.Research World(65): 75-75.
Stuart RussellSabine Hauert, Russ Altman, Manuela Veloso (2015). Robotics: ethics of artificial intelligence. Nature, 521(7553)415-418.
Wendell WallachColin AllenIva Smit (2008). Machine morality: bottom-up and top-down approaches for modelling human moral faculties. AI & SOCIETY(22): 565-582.
高泽晋系清华大学新闻与传播学院博士生。